Strategies for dealing with big data in R
Nov 24, 2019
First, we load a few R packages
suppressPackageStartupMessages({
library(here)
library(dbplyr)
library(rhdf5) # install with BiocManager::install("rhdf5")
library(HDF5Array) # install with BiocManager::install("HDF5Array")
library(pryr)
library(tidyverse)
library(rsample)
})A lot of this lecture material came from these resources:
Introduction
For most data analyses in R, data you encounter can easily be read into memory in R (either locally or on a cluster of sorts) and analyzed in a standard way. However, if you do encounter data that is too big to be read into memory, you might start to search for strategies on how to deal with this data. For most of people, it might be obvious why you would want to use R with big data, but it not obvious how.
Now, you might say advances in hardware make this less and less of a problem as most laptops come with >4-8Gb of memory and it’s easy to get instances on cloud providers with terabytes of RAM (as we saw in the last lecture). That’s definitely true. But there might be some problems that you will run into.
- Let’s say you are able load the data into the RAM on your machine (in-memory). You have to keep in mind that you will need to do something with the data too (typically need 2-3 times the RAM of the size of your data. This may or may not be a problem for your hardware that you are working with.
If you had something like a zipped .csv file, you could always try loading just the first few lines into memory to see what is inside the files, but eventually you will likely need a different strategy.
## # A tibble: 10 x 11
## mpg cyl disp hp drat wt qsec vs am gear carb
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
## 2 21 6 160 110 3.9 2.88 17.0 0 1 4 4
## 3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
## 4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
## 5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
## 6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1
## 7 14.3 8 360 245 3.21 3.57 15.8 0 0 3 4
## 8 24.4 4 147. 62 3.69 3.19 20 1 0 4 2
## 9 22.8 4 141. 95 3.92 3.15 22.9 1 0 4 2
## 10 19.2 6 168. 123 3.92 3.44 18.3 1 0 4 4- Transfer speeds can be slow. If you are working with data on a server that needs to be transferred somewhere to do the processing or computation once the data has been transferred. For example, the time it takes to make a call over the internet from San Francisco to New York City takes over 4 times longer than reading from a standard hard drive and over 200 times longer than reading from a solid state hard drive . This is an especially big problem early in developing a model or analytical project, when data might have to be pulled repeatedly.

Today we are going to discuss some stratgies (and R packages) for working with big data in R. We will also go through some examples of how to execute these strategies in R.
Motivation
Data
We will use the nycflights13 data that we learned about in our trees, bagging and boosting lecture.
If you recall:
“This package contains information about all flights that departed from NYC (e.g. EWR, JFK and LGA) to destinations in the United States, Puerto Rico, and the American Virgin Islands) in 2013: 336,776 flights in total. To help understand what causes delays, it also includes a number of other useful datasets.”
This package provides the following data tables.
flights: all flights that departed from NYC in 2013weather: hourly meterological data for each airportplanes: construction information about each planeairports: airport names and locationsairlines: translation between two letter carrier codes and names
However, this time we will cache the data from the nycflights13 package in a form we are already familiar with (SQLite databases). But there are many other data formats that you might encounter including:
.sqlite(SQL database). Talk more about this in a bit..csv(comma separated values). Good for storing rectangular data. However, can really slow to read and write, making them (often) unusable for large datasets..json(JavaScript object notation). Key-value pairs in a partially structured format.parquet(Apache Parquet). Developed by Cloudera and Twitter to serve as a column-based storage format, optimized for work with multi-column datasets. Can be used for Spark data or other tools in the Hadoop ecosystem. When you store data in parquet format, you actually get a whole directory worth of files. The data is split across multiple.parquetfiles, allowing it to be easily stored on multiple machines, and there are some metadata files too, describing the contents of each column. Can usesparklyrto import.parquetfiles.avro(Apache Avro). Released by the Hadoop working group in 2009. It is a row-based format that is highly splittable. It is also described as a data serialization system similar to Java Serialization. The schema is stored in JSON format, while the data is stored in binary format, minimizing file size and maximizing efficiency. Can usesparkavroto import.avrofiles..zarr(Zarr). Zarr files are a modern library and data format for storing chunked, compressed N-dimensional data in Python, but can work with these files using reticulate. Still very much in development though..h5(Hierarchical Data Format or HDF5). Mature (20 years old) library and data format which is also designed to handle chunked compressed N-dimensional data. Can userhdf5andHDF5Arrayto read and write.h5files.
Let’s give a brief example of one of these other file types before diving into how we will use the nycflights13 data today.
HDF5 files
Let’s create two large datasets and check the sizes of the data in memory.
A = matrix(rpois(1e8, lambda = 1), nr=1e6, nc=1e2)
B = matrix(rpois(1e6, lambda = 10), nr=1e3, nc=1e3)
pryr::object_size(A)## 400 MB## 4 MBNow let’s save them to an HDF5 file with different chunk sizes. In the first case we want to able to read from the file along columns and in the second case we want to read from the file along the rows.
The chunkdim argument controls size of chunks that you can write the data to disk. You will also end up reading from disk in these chunks. You can also control the compression behavior (0 to 9 with 9 being most compressed). The trade-off is if you have large compression, it’s good for storing a smaller file on disk, but it takes longer to read and write from disk.
## [1] TRUEA_h5 <- writeHDF5Array(x = A,
filepath = here("data", "bigdata.h5"), name = "A",
chunkdim = c(1e6,1), verbose = TRUE, level = 6)## Realizing block 1/4 ... OK, writing it ... OK
## Realizing block 2/4 ... OK, writing it ... OK
## Realizing block 3/4 ... OK, writing it ... OK
## Realizing block 4/4 ... OK, writing it ... OKB_h5 <- writeHDF5Array(x = B,
filepath = here("data", "bigdata.h5"), name = "B",
chunkdim = c(1,1e3), verbose = TRUE, level = 6)## Realizing block 1/1 ... OK, writing it ... OKIf we look at the objects A_h5 and B_h5, we see they feel like matrices that we are familiar with.
## <1000000 x 100> HDF5Matrix object of type "integer":
## [,1] [,2] [,3] [,4] ... [,97] [,98] [,99] [,100]
## [1,] 2 1 3 1 . 0 3 1 2
## [2,] 1 0 1 0 . 1 1 0 0
## [3,] 2 1 0 4 . 0 1 1 1
## [4,] 1 2 0 1 . 0 0 1 3
## [5,] 1 0 1 0 . 0 2 3 1
## ... . . . . . . . . .
## [999996,] 3 1 0 1 . 0 2 1 1
## [999997,] 3 2 1 0 . 2 1 0 2
## [999998,] 0 1 1 2 . 1 1 0 2
## [999999,] 1 0 0 4 . 1 0 0 1
## [1000000,] 3 0 1 2 . 0 3 1 1## <1000 x 1000> HDF5Matrix object of type "integer":
## [,1] [,2] [,3] [,4] ... [,997] [,998] [,999]
## [1,] 10 10 10 4 . 13 9 12
## [2,] 10 12 14 10 . 17 6 12
## [3,] 13 14 11 13 . 10 11 17
## [4,] 13 9 11 9 . 7 11 13
## [5,] 10 8 10 10 . 8 6 4
## ... . . . . . . . .
## [996,] 11 16 10 4 . 12 10 10
## [997,] 16 6 8 7 . 7 7 5
## [998,] 5 8 4 12 . 11 12 9
## [999,] 14 11 15 14 . 17 13 14
## [1000,] 8 5 15 9 . 8 10 12
## [,1000]
## [1,] 11
## [2,] 12
## [3,] 9
## [4,] 8
## [5,] 11
## ... .
## [996,] 6
## [997,] 12
## [998,] 14
## [999,] 12
## [1000,] 13But they are of a different class HDF5Matrix instead of matrix
## [1] "matrix"## [1] "matrix"We can also see what is in our .h5 file using the h5ls() function
## group name otype dclass dim
## 0 / A H5I_DATASET INTEGER 1000000 x 100
## 1 / B H5I_DATASET INTEGER 1000 x 1000Finally, we can compare the object sizes
## 400 MB## 4 MB## 2.05 kB## 2.05 kBThis is important because if we remove all the matrices, we we can just load in the HDF5 matrices
## <1000000 x 100> HDF5Matrix object of type "integer":
## [,1] [,2] [,3] [,4] ... [,97] [,98] [,99] [,100]
## [1,] 2 1 3 1 . 0 3 1 2
## [2,] 1 0 1 0 . 1 1 0 0
## [3,] 2 1 0 4 . 0 1 1 1
## [4,] 1 2 0 1 . 0 0 1 3
## [5,] 1 0 1 0 . 0 2 3 1
## ... . . . . . . . . .
## [999996,] 3 1 0 1 . 0 2 1 1
## [999997,] 3 2 1 0 . 2 1 0 2
## [999998,] 0 1 1 2 . 1 1 0 2
## [999999,] 1 0 0 4 . 1 0 0 1
## [1000000,] 3 0 1 2 . 0 3 1 1If you want to learn more how to operate with HDF5 files, check out the rhdf5 and HDF5Array packages.
Let’s clean up our space
## [1] TRUESQLite databases
OK so as mentioned above, let’s use the SQLite format to demonstrate the strategies for dealing with large data. However, they can easily transfer other data formats.
Reminder: There are several ways to query SQL or SQLite databases in R.
Ok, we will set up the SQLite database using the nycflights13_sqlite() function in the dbplyr package.
library(nycflights13)
if(!file.exists(here("data", "nycflights13", "nycflights13.sqlite"))){
dir.create(here("data", "nycflights13"))
dbplyr::nycflights13_sqlite(path=here("data", "nycflights13"))
}
# check to see what file has been created
list.files(here("data", "nycflights13"))## [1] "nycflights13.sqlite"We can use the DBI::dbConnect() function with RSQLite::SQLite() backend to connect to the SQLite database (if you want a refresher on this, check out the Getting Data lecture).
library(DBI)
conn <- DBI::dbConnect(RSQLite::SQLite(),
here("data", "nycflights13", "nycflights13.sqlite"))
conn## <SQLiteConnection>
## Path: /Users/shicks/Documents/github/teaching/jhu-advdatasci/2019/data/nycflights13/nycflights13.sqlite
## Extensions: TRUEWe can query the database with the dplyr::tbl() function that returns something that feels like a dataframe.
## # Source: lazy query [?? x 19]
## # Database: sqlite 3.29.0
## # [/Users/shicks/Documents/github/teaching/jhu-advdatasci/2019/data/nycflights13/nycflights13.sqlite]
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # … with 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dbl>## # Source: lazy query [?? x 1]
## # Database: sqlite 3.29.0
## # [/Users/shicks/Documents/github/teaching/jhu-advdatasci/2019/data/nycflights13/nycflights13.sqlite]
## n
## <int>
## 1 336776Even though it only has a few hundred thousand rows, it is still useful to demonstrate some strategies for dealing with big data in R.
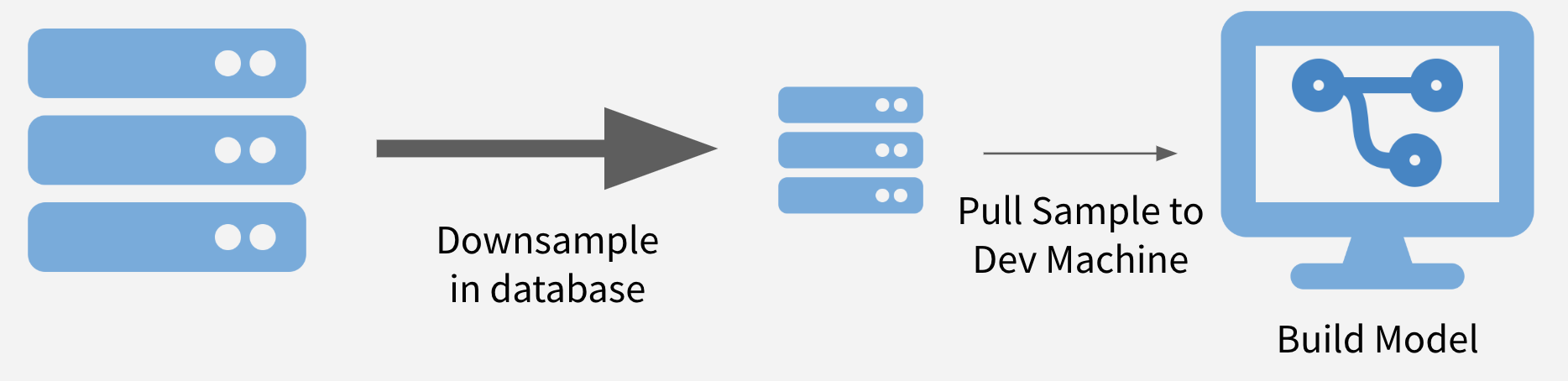
Sample and Model
The first strategy is to downsample your data to a size that can be downloaded (or if already downloaded, just loaded into memory) and perform your analysis on the downsampled data. This also allows models and methods to be run in a reasonable amount of time.
Note: If maintaining class balance is necessary (or one class needs to be over/under-sampled), it’s reasonably simple stratify the data set during sampling.
 [
[Advantages
- Speed. Relative to working on your entire data set, working on just a sample can drastically decrease run times and increase iteration speed.
- Prototyping. Even if you will eventually have to run your model on the entire data set, this can be a good way to refine hyperparameters and do feature engineering for your model.
- Packages. Since you are working on a regular, in-memory data set, you can use all your favorite R packages.
Disadvantages
- Sampling. Downsampling is not terribly difficult, but does need to be done with care to ensure that the sample is valid and that you have pulled enough points from the original data set.
- Scaling. If you are using sample and model to prototype something that will later be run on the full data set, you will need to have a strategy (such as pushing compute to the data) for scaling your prototype version back to the full data set.
- Totals. Business Intelligence (BI) – or strategies and technologies used by enterprises for the data analysis of business information (e.g. data mining, reporting, predictive analytics, etc) – tasks frequently answer questions about totals, like the count of all sales in a month. One of the other strategies is usually a better fit in this case.
Example
Let’s say we want to model whether flights will be delayed or not. We will start with some minor cleaning of the data
# Create is_delayed column in database
df <- df %>%
dplyr::mutate(is_delayed = arr_delay > 0, # Create is_delayed column
# Get just hour (currently formatted so 6 pm = 1800)
hour = sched_dep_time / 100) %>%
# Remove small carriers that make modeling difficult
dplyr::filter(!is.na(is_delayed) & !carrier %in% c("OO", "HA"))
df %>%
dplyr::count(is_delayed)## # Source: lazy query [?? x 2]
## # Database: sqlite 3.29.0
## # [/Users/shicks/Documents/github/teaching/jhu-advdatasci/2019/data/nycflights13/nycflights13.sqlite]
## is_delayed n
## <int> <int>
## 1 0 194078
## 2 1 132897These classes are reasonably well balanced, but we going to use logistic regression, so I will load a perfectly balanced sample of 40,000 data points.
For most databases, random sampling methods do not work smoothly with R.
df %>%
dplyr::sample_n(size = 1000)
# Error: `tbl` must be a data frame, not a
# `tbl_SQLiteConnection/tbl_dbi/tbl_sql/tbl_lazy/tbl` object Call
# `rlang::last_error()` to see a backtraceSo it is not suggested to use dplyr::sample_n() or dplyr::sample_frac(). So we will have to be a little more manual.
set.seed(1234)
# Create a modeling dataset
df_mod <- df %>%
# Within each class
dplyr::group_by(is_delayed) %>%
# Assign random rank
dplyr::mutate(x = random() %>% row_number()) %>%
dplyr::ungroup()# Take first 20K for each class for training set
df_train <- df_mod %>%
dplyr::group_by(is_delayed) %>%
dplyr::filter(x <= 20000) %>%
dplyr::collect() Note: dplyr::collect() forces a computation of a datbase query and retrieves data into a local tibble
# Take next 5K for test set
df_test <- df_mod %>%
dplyr::group_by(is_delayed) %>%
dplyr::filter(x > 20000 & x <= 25000) %>%
dplyr::collect() # again, this data is now loaded locally## # A tibble: 2 x 2
## # Groups: is_delayed [2]
## is_delayed n
## <int> <int>
## 1 0 20000
## 2 1 20000## # A tibble: 2 x 2
## # Groups: is_delayed [2]
## is_delayed n
## <int> <int>
## 1 0 5000
## 2 1 5000Now let’s build a model – let’s see if we can predict whether there will be a delay or not by the combination of the carrier, and the month of the flight.
## [1] "2019-12-11 11:37:54 EST"mod <- glm(is_delayed ~ carrier + as.character(month),
family = "binomial", data = df_train)
Sys.time()## [1] "2019-12-11 11:37:54 EST"##
## Call:
## glm(formula = is_delayed ~ carrier + as.character(month), family = "binomial",
## data = df_train)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.75069 -1.15093 0.01143 1.13366 1.78413
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.06832 0.05632 -1.213 0.225126
## carrierAA -0.20739 0.05607 -3.699 0.000217 ***
## carrierAS -0.56872 0.22835 -2.491 0.012755 *
## carrierB6 0.22318 0.05123 4.356 1.32e-05 ***
## carrierDL -0.20229 0.05246 -3.856 0.000115 ***
## carrierEV 0.40123 0.05157 7.781 7.19e-15 ***
## carrierF9 0.83283 0.24357 3.419 0.000628 ***
## carrierFL 0.88652 0.11167 7.939 2.04e-15 ***
## carrierMQ 0.36515 0.05753 6.347 2.19e-10 ***
## carrierUA 0.01431 0.05096 0.281 0.778856
## carrierUS -0.05498 0.06087 -0.903 0.366396
## carrierVX -0.20694 0.09115 -2.270 0.023183 *
## carrierWN 0.19011 0.06870 2.767 0.005654 **
## carrierYV 0.85876 0.28717 2.990 0.002786 **
## as.character(month)10 -0.31589 0.04958 -6.372 1.87e-10 ***
## as.character(month)11 -0.15975 0.05000 -3.195 0.001399 **
## as.character(month)12 0.47092 0.05024 9.373 < 2e-16 ***
## as.character(month)2 0.07493 0.05137 1.459 0.144626
## as.character(month)3 -0.11724 0.04975 -2.356 0.018451 *
## as.character(month)4 0.15782 0.04958 3.183 0.001457 **
## as.character(month)5 -0.19143 0.04977 -3.847 0.000120 ***
## as.character(month)6 0.18588 0.04958 3.749 0.000177 ***
## as.character(month)7 0.20797 0.04888 4.254 2.10e-05 ***
## as.character(month)8 -0.01609 0.04944 -0.325 0.744900
## as.character(month)9 -0.72687 0.05209 -13.954 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 55452 on 39999 degrees of freedom
## Residual deviance: 54104 on 39975 degrees of freedom
## AIC: 54154
##
## Number of Fisher Scoring iterations: 4# Out-of-Sample AUROC
df_test$pred <- predict(mod, newdata = df_test)
auc <- suppressMessages(pROC::auc(df_test$is_delayed, df_test$pred))
auc## Area under the curve: 0.6065As you can see, this is not a great model (and we have already shown how we can do better with this data), but that’s not the point here!
Instead, we showed how to build a model on a small subset of a big data set. Including sampling time, this took my laptop a second to run, making it easy to iterate quickly as I want to improve the model. After I’m happy with this model, I could pull down a larger sample or even the entire data set if it’s feasible, or do something with the model from the sample.
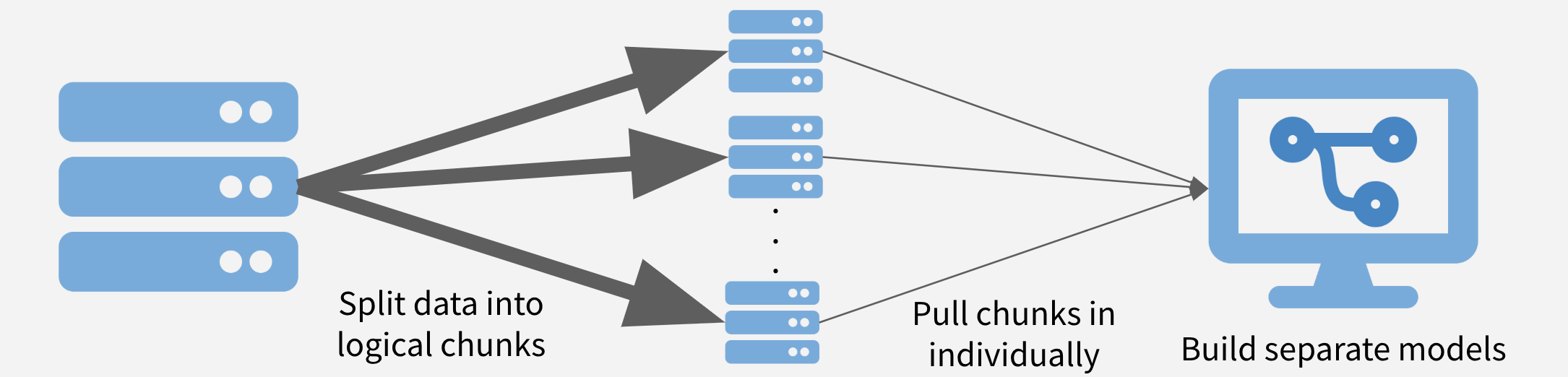
Chunk and Pull
A second strategy to chunk the data into separable units and each chunk is pulled separately and operated on serially, in parallel, or after recombining. This strategy is conceptually similar to the MapReduce algorithm – or MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters in a reliable manner – more here on MapReduce. Depending on the task at hand, the chunks might be time periods, geographic units, or logical like separate businesses, departments, products, or customer segments.
 [
[{kind=link}
{kind=link}
{kind=link}
Advantages
- Full data set. The entire data set gets used.
- Parallelization. If the chunks are run separately, the problem is easy to treat as embarassingly parallel and make use of parallelization to speed runtimes.
Disadvantages
- Need Chunks. Your data needs to have separable chunks for chunk and pull to be appropriate.
- Pull All Data. Eventually have to pull in all data, which may still be very time and memory intensive.
- Stale Data. The data may require periodic refreshes from the database to stay up-to-date since you’re saving a version on your local machine.
Example
In this case, I want to build another model of on-time arrival, but I want to do it per-carrier. This is exactly the kind of use case that is ideal for chunk and pull. I’m going to separately pull the data in by carrier and run the model on each carrier’s data.
I am going to start by just getting the complete list of the carriers.
# Get all unique carriers
carriers <- df %>%
dplyr::select(carrier) %>%
dplyr::distinct() %>%
dplyr::pull(carrier)
carriers## [1] "9E" "AA" "AS" "B6" "DL" "EV" "F9" "FL" "MQ" "UA" "US" "VX" "WN" "YV"Now, I will write a function that
- takes the name of a carrier as input
- pulls the data for that carrier into R
- splits the data into training and test
- trains the model
- outputs the out-of-sample AUROC (a common measure of model quality)
carrier_model <- function(carrier_name) {
# Pull a chunk of data
df_mod <- df %>%
dplyr::filter(carrier == carrier_name) %>%
dplyr::collect()
# Split into training and test
split <- df_mod %>%
rsample::initial_split(prop = 0.9, strata = "is_delayed") %>%
suppressMessages()
# Get training data
df_train <- split %>%
rsample::training()
# Train model
mod <- glm(is_delayed ~ as.character(month),
family = "binomial", data = df_train)
# Get out-of-sample AUROC
df_test <- split %>%
rsample::testing()
df_test$pred <- predict(mod, newdata = df_test)
suppressMessages(auc <- pROC::auc(df_test$is_delayed ~ df_test$pred))
auc
}Now, I am going to actually run the carrier model function across each of the carriers. This code runs pretty quickly, and so I do not think the overhead of parallelization would be worth it. But if I wanted to, I would replace the lapply call below with a parallel backend or use the futures package.
set.seed(1234)
mods <- lapply(carriers, carrier_model) %>%
suppressMessages()
names(mods) <- carriersLet’s look at the results.
## $`9E`
## Area under the curve: 0.5578
##
## $AA
## Area under the curve: 0.5688
##
## $AS
## Area under the curve: 0.7729
##
## $B6
## Area under the curve: 0.6164
##
## $DL
## Area under the curve: 0.5955
##
## $EV
## Area under the curve: 0.5954
##
## $F9
## Area under the curve: 0.4991
##
## $FL
## Area under the curve: 0.6305
##
## $MQ
## Area under the curve: 0.547
##
## $UA
## Area under the curve: 0.586
##
## $US
## Area under the curve: 0.5852
##
## $VX
## Area under the curve: 0.631
##
## $WN
## Area under the curve: 0.6058
##
## $YV
## Area under the curve: 0.6264So these models (again) are a little better than random chance. The point was that we utilized the chunk and pull strategy to pull the data separately by logical units and building a model on each chunk.
Push Compute to Data
A third strategy is push some of the computing to where the data are stored before moving a subset of the data out of wherever it is stored and into R. Imagine the data is compressed on a database somwhere. It is often possible to obtain significant speedups simply by doing summarization or filtering in the database before pulling the data into R.
Sometimes, more complex operations are also possible, including computing histogram and raster maps with dbplot, building a model with modeldb, and generating predictions from machine learning models with tidypredict.
Advantages
- Use the Database. Takes advantage of what databases are often best at: quickly summarizing and filtering data based on a query.
- More Info, Less Transfer. By compressing before pulling data back to R, the entire data set gets used, but transfer times are far less than moving the entire data set.
Disadvantages
- Database Operations. Depending on what database you are using, some operations might not be supported.
- Database Speed. In some contexts, the limiting factor for data analysis is the speed of the database itself, and so pushing more work onto the database is the last thing analysts want to do.
Example
In this case, I am doing a pretty simple BI task - plotting the proportion of flights that are late by the hour of departure and the airline.
Just by way of comparison, let’s run this first the naive way -– pulling all the data to my system and then doing my data manipulation to plot.
system.time(
df_plot <- df %>%
dplyr::collect() %>%
dplyr::group_by(carrier, sched_dep_time) %>%
# Get proportion per carrier-time
dplyr::summarize(delay_pct = mean(is_delayed, na.rm = TRUE)) %>%
dplyr::ungroup() %>%
# Change string times into actual times
dplyr::mutate(sched_dep_time =
stringr::str_pad(sched_dep_time, 4, "left", "0") %>%
strptime("%H%M") %>%
as.POSIXct())) -> timing1Now that wasn’t too bad, just 2.005 seconds on my laptop.
But let’s see how much of a speedup we can get from chunk and pull. The conceptual change here is significant - I’m doing as much work as possible in the SQLite server now instead of locally. But using dplyr means that the code change is minimal. The only difference in the code is that the collect() call got moved down by a few lines (to below ungroup()).
system.time(
df_plot <- df %>%
dplyr::group_by(carrier, sched_dep_time) %>%
# Get proportion per carrier-time
dplyr::summarize(delay_pct = mean(is_delayed, na.rm = TRUE)) %>%
dplyr::ungroup() %>%
dplyr::collect() %>%
# Change string times into actual times
dplyr::mutate(sched_dep_time =
stringr::str_pad(sched_dep_time, 4, "left", "0") %>%
strptime("%H%M") %>%
as.POSIXct())) -> timing2It might have taken you the same time to read this code as the last chunk, but this took only 0.542 seconds to run, almost an order of magnitude faster! That’s pretty good for just moving one line of code.
Now that we have done a speed comparison, we can create the nice plot we all came for.
df_plot %>%
dplyr::mutate(carrier = paste0("Carrier: ", carrier)) %>%
ggplot(aes(x = sched_dep_time, y = delay_pct)) +
geom_line() +
facet_wrap("carrier") +
ylab("Proportion of Flights Delayed") +
xlab("Time of Day") +
scale_y_continuous(labels = scales::percent) +
scale_x_datetime(date_breaks = "4 hours",
date_labels = "%H")
It looks to me like flights later in the day might be a little more likely to experience delays, which we saw in our last class with this data. However, here we have learned how to work with data not necessarily loaded in memory.
Summary
There are lots of ways you can work with large data in R. A few that we learned about today include
- Sample and model
- Chunk and pull
- Push compute to data
Hopefully this will help the next time you encounter a large dataset in R.